Fast and Elegant Scraping Framework for Gophers Colly provides a clean interface to write any kind of crawler/scraper/spider
With Colly you can easily extract structured data from websites, which can be used for a wide range of applications, like data mining, data processing or archiving.
Install 1 go get -u github.com /gocolly/colly/...
Getting started 1 import "github.com/gocolly/colly"
Collector Colly’s main entity.
Manages the network communication and responsible for the execution of the attached callbacks while a collector job is running.
To work with colly, you have to initialize a Collector:
1 c := colly.NewCollector()
Callbacks Attach different type of callback functions to a Collector to control a collecting job or retrieve information.
Add callbacks to a Collector 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 func (r *colly.Request) "Visiting" , r.URL)func (_ *colly.Response, err error ) "Something went wrong:" , err)func (r *colly.Response) "Visited" , r.Request.URL)"a[href]" , func (e *colly.HTMLElement) "href" ))"tr td:nth-of-type(1)" , func (e *colly.HTMLElement) "First column of a table row:" , e.Text)"//h1" , func (e *colly.XMLElement) func (r *colly.Response) "Finished" , r.Request.URL)
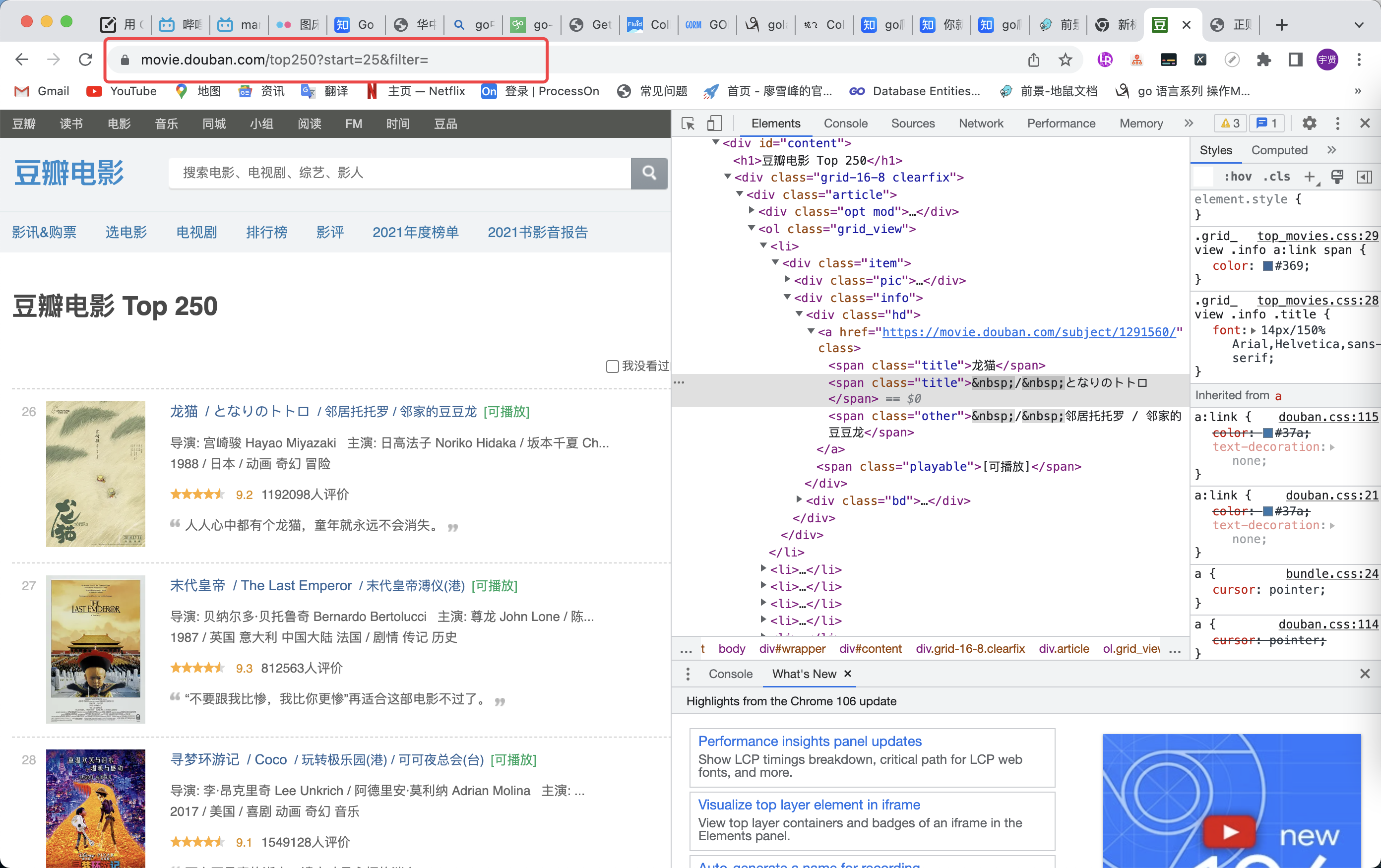
Combat 豆瓣 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 package mainimport ("fmt" "github.com/PuerkitoBio/goquery" "github.com/gocolly/colly" "github.com/gocolly/colly/extensions" "regexp" "strings" "time" func main () 1 func (c *colly.Collector) true "^(https://movie\\.douban\\.com/top250)\\?start=[0-9].*&filter=" ),"a[href]" , func (e *colly.HTMLElement) "href" )"div.info" , func (e *colly.HTMLElement) func (i int , selection *goquery.Selection) "span.title" ).First().Text()"div.bd p" ).First().Text()), " " )"p.quote span.inq" ).Text()"%d --> %s:%s %s\n" , number, movies, director, quote)1 func (response *colly.Response, err error ) "https://movie.douban.com/top250?start=0&filter=" )"花费时间:%s" , time.Since(t))
Step1 创建收集器 1 2 3 4 5 6 7 8 9 10 c := colly.NewCollector(func (c *colly.Collector) true "^(https://movie\\.douban\\.com/top250)\\?start=[0-9].*&filter=" ),
Step2 HTML回调 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 "a[href]" , func (e *colly.HTMLElement) "href" )"div.info" , func (e *colly.HTMLElement) func (i int , selection *goquery.Selection) "span.title" ).First().Text()"div.bd p" ).First().Text()), " " )"p.quote span.inq" ).Text()"%d --> %s:%s %s\n" , number, movies, director, quote)1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 <div class ="info" > <div class ="hd" > <a href ="https://movie.douban.com/subject/1291546/" class ="" > <span class ="title" > 霸王别姬</span > <span class ="other" > / 再见,我的妾 / Farewell My Concubine</span > </a > <span class ="playable" > [可播放]</span > </div > <div class ="bd" > <p class ="" > &nbsqp; 主演: 张国荣 Leslie Cheung / 张丰毅 Fengyi Zha...<br > / 中国大陆 中国香港 / 剧情 爱情 同性</p > <div class ="star" > <span class ="rating5-t" > </span > <span class ="rating_num" property ="v:average" > 9.6</span > <span property ="v:best" content ="10.0" > </span > <span > 2008403人评价</span > </div > <p class ="quote" > <span class ="inq" > 风华绝代。</span > </p > </div > </div >
Step3 错误处理,回调页面 1 2 3 4 5 6 c.OnError(func (response *colly.Response, err error ) "https://movie.douban.com/top250?start=0&filter=" )"花费时间:%s" , time.Since(t))